Redux Essentials,第八节:RTK 查询高级模式
你将学到
- 如何使用带有 ID 的标签来管理缓存失效和重新获取
- 如何在 React 之外使用 RTK 查询缓存
- 处理响应数据的技术
- Implementing optimistic updates and streaming updates
预置知识
- 完成 第 7 部分 以了解 RTK Query 设置和基本用法
简介
在 第 7 部分:RTK 查询基础知识 中,我们了解了如何设置和使用 RTK Query API 来处理应用程序中的数据获取和缓存。我们在 Redux 存储中添加了一个 “API slice ”,定义了查询请求接口来获取帖子数据,以及一个 “Mutate” 请求接口来添加新帖子。
在本节中,我们将继续迁移我们的示例应用程序以将 RTK Query 用于其他数据类型,并了解如何使用其一些高级功能来简化代码库并改善用户体验。
info
本节中的某些更改并非绝对必要 - 包含这些更改是为了演示 RTK Query 的功能并展示你 可以 做的一些事情,因此你可以在需要时了解如何使用这些功能。
编辑帖子
我们已经添加了一个 mutation 请求接口来将新的 Post 条目保存到服务器,并在我们的 <AddPostForm> 中使用它。接下来,我们需要处理更新 <EditPostForm> 让我们可以编辑现有帖子。
更新编辑帖子表单
与添加帖子一样,第一步是在我们的 API Slice 中定义一个新的 mutation 请求接口。这看起来很像添加帖子的 mutation,但请求接口需要在 URL 中包含帖子 ID 并使用 HTTP PATCH 请求来指出它正在更新某些字段。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation({
query: post => ({
url: `/posts/${post.id}`,
method: 'PATCH',
body: post
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
添加后,我们可以更新 <EditPostForm>。它需要从 store 中读取原始的 Post 条目,使用它来初始化组件状态以编辑字段,然后将更新的更改发送到服务器。目前,我们正在使用 selectPostById 读取 Post 条目,并为请求手动调度 postUpdated thunk。
我们可以使用我们在 <SinglePostPage> 中使用的相同 useGetPostQuery Hook 从存储中的缓存中读取 Post 条目,并将使用新的 useEditPostMutation Hook 来处理保存更改。
import React, { useState } from 'react'
import { useHistory } from 'react-router-dom'
import { Spinner } from '../../components/Spinner'
import { useGetPostQuery, useEditPostMutation } from '../api/apiSlice'
export const EditPostForm = ({ match }) => {
const { postId } = match.params
const { data: post } = useGetPostQuery(postId)
const [updatePost, { isLoading }] = useEditPostMutation()
const [title, setTitle] = useState(post.title)
const [content, setContent] = useState(post.content)
const history = useHistory()
const onTitleChanged = e => setTitle(e.target.value)
const onContentChanged = e => setContent(e.target.value)
const onSavePostClicked = async () => {
if (title && content) {
await updatePost({ id: postId, title, content })
history.push(`/posts/${postId}`)
}
}
// omit rendering logic
}
缓存数据订阅生命周期
让我们试试这个,看看会发生什么。打开浏览器的 DevTools,转到 Network 选项卡,然后刷新主页。当我们获取初始数据时,你应该会看到对 /posts 的 GET 请求。当你单击 “View Post” 按钮时,你应该会看到对 /posts/:postId 的第二个请求,该请求返回该单个帖子条目。
现在单击单个帖子页面内的 “Edit Post”。UI 切换到 <EditPostForm>,但这次没有针对单个帖子的网络请求。为什么没有?
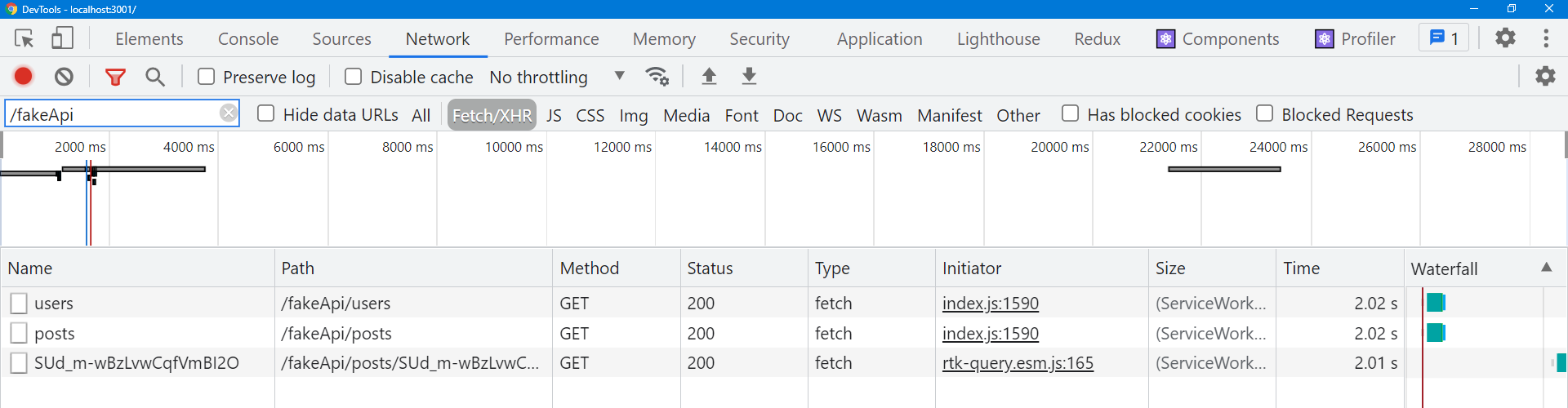
RTK Query 允许多个组件订阅相同的数据,并且将确保每个唯一的数据集只获取一次。 在内部,RTK Query 为每个请求接口 + 缓存键组合保留一个 action 订阅的引用计数器。如果组件 A 调用 useGetPostQuery(42),则将获取该数据。如果组件 B 挂载并调用 useGetPostQuery(42),则请求的数据完全相同。两种钩子用法将返回完全相同的结果,包括获取的 “data” 和加载状态标志。
当活跃订阅数下降到 0 时,RTK Query 会启动一个内部计时器。 如果在添加任何新的数据订阅之前计时器到期,RTK Query 将自动从缓存中删除该数据,因为应用程序不再需要该数据。但是,如果在计时器到期之前添加了新订阅,则取消计时器,并使用已缓存的数据而无需重新获取它。
在这种情况下,我们的 <SinglePostPage> 挂载并通过 ID 请求单个 Post。当我们点击 “Edit Post” 时,<SinglePostPage> 组件被路由器卸载,并且活动订阅由于卸载而被删除。RTK Query 立即启动 “remove this post data” 计时器。但是,<EditPostPage> 组件会立即挂载并使用相同的缓存键订阅相同的 Post 数据。因此,RTK Query 取消了计时器并继续使用相同的缓存数据,而不是从服务器获取数据。
默认情况下,未使用的数据会在 60 秒后从缓存中删除,但这可以在根 API Slice 定义中进行配置,也可以使用 keepUnusedDataFor 标志在各个请求接口定义中覆盖,该标志指定缓存生存期 秒。
使特定项目无效
我们的 <EditPostForm> 组件现在可以将编辑后的帖子保存到服务器,但是我们遇到了一个问题。如果我们在编辑时单击 “Save Post”,它会将我们返回到 <SinglePostPage>,但仍然显示没有编辑的旧数据。<SinglePostPage> 仍在使用之前获取的缓存 Post 条目。就此而言,如果我们返回主页面并查看 <PostsList>,它也会显示旧数据。我们需要一种方法来强制重新获取 所有 单个帖子条目和整个帖子列表。
早些时候,我们看到了如何使用标签使部分缓存数据无效。我们声明 getPosts 查询请求接口 提供 了 'Post' 标签,而 addNewPost mutation 请求接口使相同的 'Post' 标签 无效。这样,每次添加新帖子时,我们都会强制 RTK Query 从 getQuery 请求接口重新获取整个帖子列表。
我们可以在 getPost 查询和 editPost mutation 中添加一个 'Post' 标签,但这会强制所有其他单独的帖子也被重新获取。幸运的是,RTK Query 让我们可以定义特定的标签,这让我们在无效数据方面更有选择性。这些特定标签看起来像 {type: 'Post', id: 123}。
我们的 getPosts 查询定义了一个 providesTags 字段,它是一个字符串数组。providesTags 字段还可以接受一个回调函数,该函数接收 result 和 arg,并返回一个数组。这允许我们根据正在获取的数据的 ID 创建标签条目。同样,invalidatesTags 也可以是回调。
为了获得正确的行为,我们需要使用正确的标签设置每个请求接口:
getPosts:为整个列表提供一个通用的'Post'标签,以及为每个接收到的帖子对象提供一个特定的{type: 'Post', id}标签getPost:为单个 post 对象提供特定的{type: 'Post', id}对象addNewPost:使一般的'Post'标签无效,重新获取整个列表editPost:使特定的{type: 'Post', id}标签无效。这将强制重新获取 “getPost” 中的个人帖子以及 “getPosts” 中的整个帖子列表,因为它们都提供了与 “{type, id}” 值匹配的标签。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts',
providesTags: (result = [], error, arg) => [
'Post',
...result.map(({ id }) => ({ type: 'Post', id }))
]
}),
getPost: builder.query({
query: postId => `/posts/${postId}`,
providesTags: (result, error, arg) => [{ type: 'Post', id: arg }]
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
}),
invalidatesTags: (result, error, arg) => [{ type: 'Post', id: arg.id }]
})
})
})
如果响应没有数据或有错误,这些回调中的 result 参数可能是未定义的,因此我们必须安全地处理它。对于 getPosts,我们可以通过使用默认的参数数组值映射来做到这一点,而对于 getPost,我们已经根据参数 ID 返回了一个单项数组。对于 editPost,我们从传递给触发器函数的部分帖子对象中知道帖子的 ID,因此我们可以从那里读取它。
完成这些更改后,让我们返回并尝试再次编辑帖子,并在浏览器 DevTools 中打开 Network 选项卡。
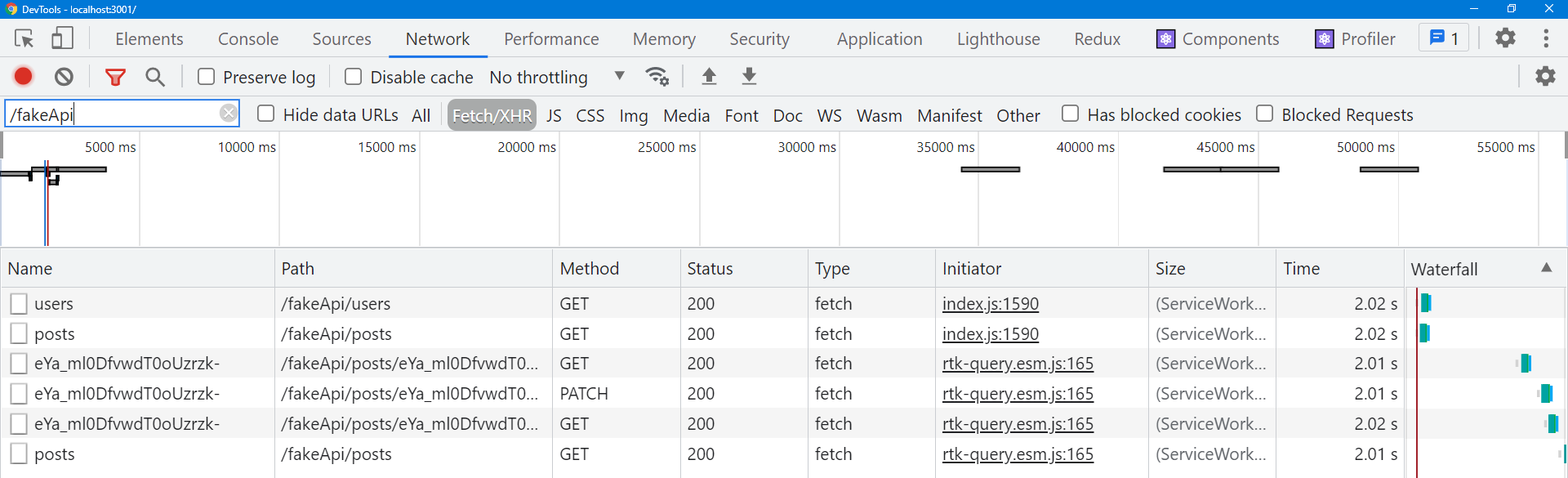
这次保存编辑后的帖子时,我们应该看到两个请求连续发生:
- 来自
editPostmutation 的PATCH /posts/:postId - 重新获取作为
getPost查询的GET /posts/:postId
然后,如果我们单击返回主帖子选项卡,我们还应该看到:
- 重新获取作为
getPosts查询的GET /posts
因为我们使用标签提供了请求接口之间的关系,RTK Query 知道当我们进行编辑并且具有该 ID 的特定标签无效时,它需要重新获取单个帖子和帖子列表 - 无需进一步更改!同时,在我们编辑帖子时,getPosts 数据的缓存删除计时器已过期,因此已将其从缓存中删除。当我们再次打开 <PostsList> 组件时,RTK Query 发现它没有缓存中的数据并重新获取它。
这里有一个警告。通过在 getPosts 中指定一个普通的 'Post' 标记并在 addNewPost 中使其无效,我们实际上最终也会强制重新获取所有 个人 帖子。如果我们真的只想重新获取 getPost 请求接口的帖子列表,你可以包含一个具有任意 ID 的附加标签,例如 {type: 'Post', id: 'LIST'},并使该标签无效。 RTK 查询文档有 [一个描述如果某些通用/特定标签组合失效会发生什么的表格](https://redux-toolkit.js.org/rtk-query/usage/automated-refetching#tag-invalidation-behavior)。
info
RTK Query 有许多其他选项可用于控制何时以及如何重新获取数据,包括条件获取、延迟查询和预取,并且可以通过多种方式自定义查询定义。有关使用这些功能的更多详细信息,请参阅 RTK 查询使用指南文档:
管理用户数据
我们已完成将帖子数据管理转换为使用 RTK Query。接下来,我们将转换用户列表。
由于我们已经了解了如何使用 RTK Query Hooks 来获取和读取数据,因此在本节中我们将尝试不同的方法。RTK Query 的核心 API 与 UI 无关,可以与任何 UI 层一起使用,而不仅仅是 React。通常你应该坚持使用 hooks,但在这里我们将 只 使用 RTK Query 核心 API 来处理用户数据,以便你了解如何使用它。
手动获取用户
我们目前正在 usersSlice.js 中定义 fetchUsers 异步 thunk,并在 index.js 中手动调度该 thunk,以便用户列表尽快可用。我们可以使用 RTK Query 执行相同的过程。
我们将首先在 apiSlice.js 中定义一个 getUsers 查询请求接口,类似于我们现有的请求接口。我们将导出 useGetUsersQuery hook 只是为了保持一致性,但现在我们不打算使用它。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// 忽略部分依赖
getUsers: builder.query({
query: () => '/users'
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useGetUsersQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
如果我们检查 API slice 对象,它包含一个 endpoints 字段,我们定义的每个请求接口都有一个请求接口对象。

每个请求接口对象包含:
- 我们从根 API slice 对象导出的相同主 query/mutation hooks,但命名为
useQuery或useMutation - 对于查询请求接口,一组额外的 query hook 用于惰性查询或部分订阅等场景
- 一组 "matcher" 实用程序 用于检查由对该请求接口的请求 dispatch 的
pending/fulfilled/rejectedaction - 触发对此请求接口的请求的
initiatethunk - 一个
select函数,创建 memoized selectors,可以检索缓存的结果数据 + 此请求接口的状态条目
如果我们想在 React 之外获取用户列表,我们可以在我们的索引文件中调度 getUsers.initiate() thunk:
// 忽略部分依赖
import { apiSlice } from './features/api/apiSlice'
async function main() {
// 启动 mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSlice.endpoints.getUsers.initiate())
ReactDOM.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>,
document.getElementById('root')
)
}
main()
这种 dispatch 在 query hooks 内自动发生,但如果需要,我们可以手动启动它。
caution
手动 dispatch RTKQ 请求 thunk 将创建一个订阅条目,但随后由你决定[稍后取消订阅该数据](https://redux-toolkit.js.org/rtk-query/usage/usage-without-react -hooks#removing-a-subscription) - 否则数据将永久保留在缓存中。在这种情况下,总是需要用户数据,所以我们可以跳过退订。
选择用户数据
我们目前有像 selectAllUsers 和 selectUserById 这样的 selector,它们是由我们的 createEntityAdapter 用户适配器生成的,并且从 state.users 中读取。如果我们重新加载页面,我们所有与用户相关的显示都会被破坏,因为 state.users slice 没有数据。 现在我们正在为 RTK Query 的缓存获取数据,我们应该将这些 selector 替换为从缓存中读取的等价物。
API slice 请求接口中的 endpoint.select() 函数将在我们每次调用它时创建一个新的 memoized selector 函数。select() 将缓存键作为其参数,并且这必须与你作为参数传递给 query hook 或 initiate() thunk 的缓存键相同。生成的 selector 使用该缓存键来准确知道它应该从存储中的缓存状态返回哪个缓存结果。
在这种情况下,我们的 getUsers 请求接口不需要任何参数——我们总是获取整个用户列表。 所以,我们可以创建一个不带参数的 cache selector,缓存键变成 undefined。
import {
createSlice,
createEntityAdapter,
createSelector
} from '@reduxjs/toolkit'
import { apiSlice } from '../api/apiSlice'
/* 暂时忽略适配器 - 我们很快会再次使用它
const usersAdapter = createEntityAdapter()
const initialState = usersAdapter.getInitialState()
*/
// 调用 `someEndpoint.select(someArg)` 会生成一个新的 selector,该 selector 将返回
// 带有这些参数的查询的查询结果对象。
// 要为特定查询参数生成 selector,请调用 `select(theQueryArg)`。
// 在这种情况下,用户查询没有参数,所以我们不向 select() 传递任何内容
export const selectUsersResult = apiSlice.endpoints.getUsers.select()
const emptyUsers = []
export const selectAllUsers = createSelector(
selectUsersResult,
usersResult => usersResult?.data ?? emptyUsers
)
export const selectUserById = createSelector(
selectAllUsers,
(state, userId) => userId,
(users, userId) => users.find(user => user.id === userId)
)
/* 暂时忽略 selector——我们稍后再讨论
export const {
selectAll: selectAllUsers,
selectById: selectUserById,
} = usersAdapter.getSelectors((state) => state.users)
*/
一旦我们有了初始的 selectUsersResult selector,我们可以将现有的 selectAllUsers selector 替换为从缓存结果中返回用户数组的 selector,然后将 selectUserById 替换为从该数组中找到正确用户的 selector。
现在我们要从 usersAdapter 中注释掉那些 selector——稍后我们将进行另一项更改,切换回使用这些 selector。
我们的组件已经在导入 selectAllUsers 和 selectUserById,所以这个更改应该可以正常工作!尝试刷新页面并单击帖子列表和单个帖子视图。 正确的用户名应该出现在每个显示的帖子中,以及 <AddPostForm> 的下拉列表中。
由于 usersSlice 根本不再被使用,我们可以继续从该文件中删除 createSlice 调用,并从我们的 store 设置中删除 users: usersReducer。我们仍然有一些引用 postsSlice 的代码,所以还不能完全删除它——我们很快就会解决这个问题。
注入请求接口
大型应用程序通常会将功能代码拆分到单独的包中,然后在首次使用该功能时按需延迟加载它们。我们说过 RTK Query 通常每个应用程序都有一个 “API slice”,到目前为止,我们已经直接在 apiSlice.js 中定义了所有请求接口。如果我们想对一些请求接口定义进行代码拆分,或者将它们移动到另一个文件中以防止 API slice 文件变得太大,会发生什么?
RTK Query 支持使用 apiSlice.injectEndpoints() 拆分请求接口定义。这样,我们仍然可以拥有一个带有单个 middleware 和 cache reducer 的 API slice,但我们可以将一些请求接口的定义移动到其他文件中。这可以实现代码拆分方案,以及在需要时将一些请求接口与功能文件夹放在一起。
为了说明这个过程,让我们将 getUsers 请求接口切换到 usersSlice.js 中,而不是在 apiSlice.js 中定义。
我们已经将 apiSlice 导入到 usersSlice.js 中,以便可以访问 getUsers 请求接口,因此可以切换到在这里调用 apiSlice.injectEndpoints()。
import { apiSlice } from '../api/apiSlice'
export const extendedApiSlice = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query({
query: () => '/users'
})
})
})
export const { useGetUsersQuery } = extendedApiSlice
export const selectUsersResult = extendedApiSlice.endpoints.getUsers.select()
injectEndpoints() 改变原始 API slice 对象以添加额外的请求接口定义,然后返回它。我们最初添加到存储中的实际 cache reducer 和 middleware 仍然可以正常工作。此时,apiSlice 和 extendedApiSlice 是同一个对象,但在这里参考 extendedApiSlice 对象而不是 apiSlice 会有所帮助,提醒自己。(如果你使用的是 TypeScript,这一点更为重要,因为只有 extendedApiSlice 值具有为新请求接口添加的类型。)
目前,唯一引用 getUsers 请求接口的文件是我们的索引文件,它正在 dispatch initiate thunk。我们需要更新它以导入扩展的 API slice:
// 忽略部分依赖
- import { apiSlice } from './features/api/apiSlice'
+ import { extendedApiSlice } from './features/users/usersSlice'
async function main() {
// 启动 mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
- store.dispatch(apiSlice.endpoints.getUsers.initiate())
+ store.dispatch(extendedApiSlice.endpoints.getUsers.initiate())
ReactDOM.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>,
document.getElementById('root')
)
}
main()
或者,你可以只从 slice 文件中导出特定请求接口本身。
处理响应数据
到目前为止,我们所有的查询请求接口都只是简单地存储了来自服务器的响应数据,就像它在正文中收到的一样。getPosts 和 getUsers 都期望服务器返回一个数组,而 getPost 期望单独的 Post 对象作为主体。
客户端通常需要从服务器响应中提取数据片段,或者在缓存数据之前以某种方式转换数据。例如,如果 /getPost 请求返回一个像 {post: {id}} 这样的主体,并且数据嵌套了怎么办?
有几种方法可以让我们在概念上处理这个问题。 一种选择是提取 “responseData.post” 字段并将其存储在缓存中,而不是整个正文。另一种是将整个响应数据存储在缓存中,但让我们的组件仅指定他们需要的缓存数据的特定部分。
转换响应
请求接口可以定义一个 transformResponse 处理程序,该处理程序可以在缓存之前提取或修改从服务器接收到的数据。对于 getPost 示例,我们可以有 transformResponse: (responseData) => responseData.post,它只会缓存实际的 Post 对象,而不是整个响应体。
在 第 6 部分:性能和规范化 中,我们讨论了将数据存储在归一化结构中有用的原因。特别是,它让我们可以根据 ID 查找和更新项目,而不必遍历数组来查找正确的项目。
我们的 selectUserById selector 当前必须遍历缓存的用户数组才能找到正确的 User 对象。如果我们要使用归一化方法转换要存储的响应数据,我们可以将其简化为直接通过 ID 查找用户。
我们之前在 usersSlice 中使用 createEntityAdapter 来管理归一化用户数据。现在可以将 createEntityAdapter 集成到我们的 extendedApiSlice 中,并实际使用 createEntityAdapter 在数据缓存之前对其进行转换。并且将取消注释我们最初拥有的 usersAdapter 行,并再次使用它的更新函数和 selector。
import { apiSlice } from '../api/apiSlice'
const usersAdapter = createEntityAdapter()
const initialState = usersAdapter.getInitialState()
export const extendedApiSlice = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query({
query: () => '/users',
transformResponse: responseData => {
return usersAdapter.setAll(initialState, responseData)
}
})
})
})
export const { useGetUsersQuery } = extendedApiSlice
// 调用 `someEndpoint.select(someArg)` 生成一个新的 selector,该 selector将返回
// 带有这些参数的查询的查询结果对象。
// 要为特定查询参数生成 selector,请调用 `select(theQueryArg)`。
// 在这种情况下,用户查询没有参数,所以我们不向 select() 传递任何内容
export const selectUsersResult = extendedApiSlice.endpoints.getUsers.select()
const selectUsersData = createSelector(
selectUsersResult,
usersResult => usersResult.data
)
export const { selectAll: selectAllUsers, selectById: selectUserById } =
usersAdapter.getSelectors(state => selectUsersData(state) ?? initialState)
我们在 getUsers 请求接口添加了一个 transformResponse 选项。它接收整个响应数据体作为其参数,并应返回要缓存的实际数据。通过调用usersAdapter.setAll(initialState, responseData),它将返回标准的 {ids: [],entities: {}} 归一化数据结构,包含所有接收到的项目。
adapter.getSelectors() 函数需要给定一个输入 selector,以便它知道在哪里可以找到归一化数据。在这种情况下,数据嵌套在 RTK Query cache reducer 中,因此我们从缓存状态中选择正确的字段。
归一化 vs 文档缓存
值得花一点时间来讨论一下我们刚刚做了什么。
你可能听说过与 Apollo 等其他数据获取库相关的术语归一化缓存。重要的是要了解 RTK Query 使用文档缓存方法,而不是归一化缓存。
一个完全归一化的缓存会尝试根据项目类型和 ID 对 所有 查询中的相似项目进行重复数据删除。例如,假设我们有一个带有 getTodos 和 getTodo 请求接口的 API slice,并且我们的组件进行以下查询:
getTodos()getTodos({filter: 'odd'})getTodo({id: 1})
这些查询结果中的每一个都将包含一个类似于 {id: 1} 的 Todo 对象。
在完全归一化的去重缓存中,只会存储这个 Todo 对象的一个副本。但是,RTK Query 将每个查询结果独立保存在缓存中。因此,这将导致此 Todo 的三个单独副本缓存在 Redux store 中。但是,如果所有请求接口都始终提供相同的标签(例如 {type: 'Todo', id: 1}),则使该标签无效,迫使所有匹配的请求接口重新获取其数据以保持一致性。
RTK Query 故意没有实现一个缓存,该缓存会在多个请求中对相同的项目进行重复数据删除。有几个原因:
- 完全规范化的跨查询共享缓存是一个很难解决的问题
- 我们现在没有时间、资源或兴趣尝试解决这个问题
- 在许多情况下,在数据失效时简单地重新获取数据效果很好并且更容易理解
- RTKQ 至少可以帮助解决 “获取一些数据” 的一般用例,这是很多人的一大痛点
相比之下,我们只是将 getUsers 请求接口的响应数据归一化,因为它被存储为 {[id]: value} 查找表。然而,这 不 与 “归一化缓存” 相同——我们只转换了 如何存储这个响应,而不是跨请求接口或请求对结果进行重复数据删除。
从结果中选择值
从旧的 postsSlice 读取的最后一个组件是 <UserPage>,它根据当前用户过滤帖子列表。我们已经看到,可以使用 useGetPostsQuery() 获取整个帖子列表,然后在组件中对其进行转换,例如在 useMemo 中进行排序。query hooks 还使我们能够通过提供 selectFromResult 选项来选择缓存状态的片段,并且仅在所选片段更改时重新渲染。
我们可以使用 selectFromResult 让 <UserPage> 从缓存中读取过滤后的帖子列表。然而,为了让 selectFromResult 避免不必要的重新渲染,我们需要确保我们提取的任何数据都被正确记忆。为此,我们应该创建一个新的 selector 实例,<UsersPage> 组件可以在每次渲染时重用它,以便 selector 根据其输入来记忆结果。
import { createSelector } from '@reduxjs/toolkit'
import { selectUserById } from '../users/usersSlice'
import { useGetPostsQuery } from '../api/apiSlice'
export const UserPage = ({ match }) => {
const { userId } = match.params
const user = useSelector(state => selectUserById(state, userId))
const selectPostsForUser = useMemo(() => {
const emptyArray = []
// 返回此页面的唯一 selector 实例,以便
// 过滤后的结果被正确记忆
return createSelector(
res => res.data,
(res, userId) => userId,
(data, userId) => data?.filter(post => post.user === userId) ?? emptyArray
)
}, [])
// 使用相同的帖子查询,但仅提取其部分数据
const { postsForUser } = useGetPostsQuery(undefined, {
selectFromResult: result => ({
// 我们可以选择在此处包含结果中的其他元数据字段
...result,
// 在 hook 结果对象中包含一个名为 “postsForUser” 的字段,
// 这将是一个过滤的帖子列表
postsForUser: selectPostsForUser(result, userId)
})
})
// omit rendering logic
}
我们在这里创建的 memoized selector 函数有一个关键的区别。通常,selector 期望整个 Redux state 作为它们的第一个参数,并从 state 中提取或派生一个值。但是,在这种情况下,我们只处理保存在缓存中的 “result” 值。result 对象内部有一个 “data” 字段,其中包含我们需要的实际值,以及一些请求元数据字段。
我们的 selectFromResult 回调从服务器接收包含原始请求元数据和 data 的 result 对象,并且应该返回一些提取或派生的值。因为 query hooks 为这里返回的任何内容添加了一个额外的 refetch 方法,所以最好始终从 selectFromResult 返回一个对象,其中包含你需要的字段。
由于 result 保存在 Redux 存储中,我们不能改变它 - 我们需要返回一个新对象。query hooks 将对返回的对象进行浅层比较,并且仅在其中一个字段发生更改时才重新渲染组件 我们可以通过仅返回此组件所需的特定字段来优化重新渲染 - 如果我们不需要其余的元数据标志,我们可以完全省略它们。如果你确实需要它们,你可以传播原始的 result 值以将它们包含在输出中。
在这种情况下,我们将调用字段 “postsForUser”,我们可以从 hook 结果中解构这个新字段。通过每次调用 selectPostsForUser(result, userId),它会记住过滤后的数组,只有在获取的数据或用户ID发生变化时才会重新计算。
比较转换方法
我们现在已经看到了三种不同的方式来管理转换响应:
- 将原始响应保存在缓存中,读取组件中的完整结果并导出值
- 将原始响应保存在缓存中,使用
selectFromResult读取派生结果 - 在存储到缓存之前转换响应
这些方法中的每一种都可以在不同的情况下有用。 以下是你何时应该考虑使用它们的一些建议:
transformResponse:请求接口的所有消费者都需要特定的格式,例如标准化响应以实现更快的 ID 查找selectFromResult:请求接口的一些消费者只需要部分数据,例如过滤列表- per-component /
useMemo:当只有某些特定组件需要转换缓存数据时
高级缓存更新
我们已经完成更新我们的帖子和用户数据,所以剩下的就是处理反应和通知。将这些切换为使用 RTK Query 将使我们有机会尝试一些可用于处理 RTK Query 缓存数据的高级技术,并使我们能够为用户提供更好的体验。
持续反应
最初,我们只跟踪客户端的反应,并没有将它们持久化到服务器。让我们添加一个新的 addReaction mutation,并在每次用户单击反应按钮时使用它来更新服务器上相应的 Post。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// 忽略部分依赖
addReaction: builder.mutation({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// 在一个真实的应用程序中,我们可能需要以某种方式基于用户 ID
// 这样用户就不能多次做出相同的反应
body: { reaction }
}),
invalidatesTags: (result, error, arg) => [
{ type: 'Post', id: arg.postId }
]
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation,
useAddReactionMutation
} = apiSlice
与我们的其他 mutations 类似,我们获取一些参数并向服务器发出请求,请求正文中包含一些数据。由于这个示例应用程序很小,我们将只给出反应的名称,并让服务器在这篇文章中为该反应类型增加计数器。
我们已经知道我们需要重新获取此帖子才能查看客户端上的任何数据更改,因此我们可以根据其 ID 使这个特定的帖子条目无效。
有了这些,让我们更新 <ReactionButtons> 以使用这个 mutations。
import React from 'react'
import { useAddReactionMutation } from '../api/apiSlice'
const reactionEmoji = {
thumbsUp: '👍',
hooray: '🎉',
heart: '❤️',
rocket: '🚀',
eyes: '👀'
}
export const ReactionButtons = ({ post }) => {
const [addReaction] = useAddReactionMutation()
const reactionButtons = Object.entries(reactionEmoji).map(
([reactionName, emoji]) => {
return (
<button
key={reactionName}
type="button"
className="muted-button reaction-button"
onClick={() => {
addReaction({ postId: post.id, reaction: reactionName })
}}
>
{emoji} {post.reactions[reactionName]}
</button>
)
}
)
return <div>{reactionButtons}</div>
}
让我们看看这个在行动!转到主 <PostsList>,然后单击其中一个反应以查看会发生什么。
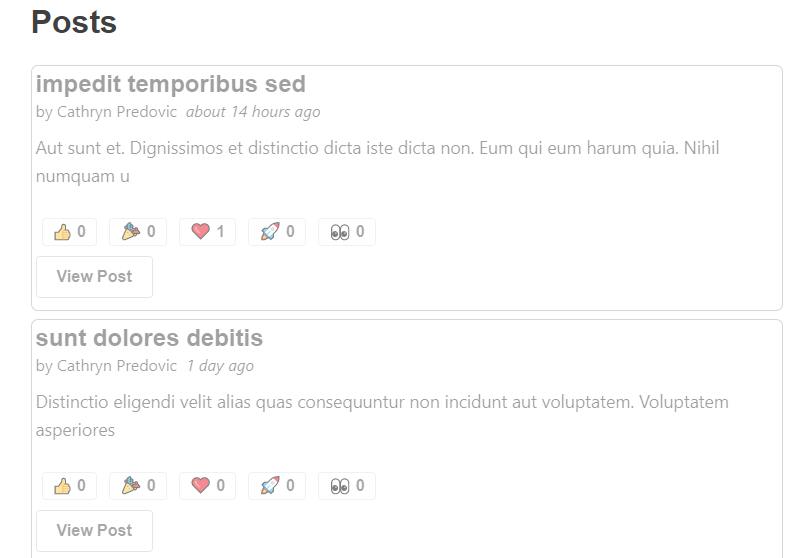
整个 <PostsList> 组件是灰色的,因为我们刚刚重新获取了整个帖子列表以响应更新的帖子。很明显这是故意,因为我们的模拟 API 服务器被设置为在响应之前有 2 秒的延迟,但是即使响应更快,这仍然不是一个好的用户体验。
实施 Optimistic Updates
对于像添加反应这样的小更新,我们可能不需要重新获取整个帖子列表。相反,我们可以尝试只更新客户端上已经缓存的数据,以匹配我们期望在服务器上发生的数据。此外,如果我们立即更新缓存,用户在单击按钮时会立即获得反馈,而不必等待响应返回。这种立即更新客户端状态的方法称为 “Optimistic Updates”,它是 Web 应用程序中的常见模式。
RTK Query 允许你通过基于请求生命周期处理程序修改客户端缓存来实现 Optimistic Updates。请求接口可以定义一个 onQueryStarted 函数,该函数将在请求开始时调用,我们可以在该处理程序中运行其他逻辑。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// 忽略部分依赖
addReaction: builder.mutation({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// 在一个真实的应用程序中,我们可能需要以某种方式基于用户 ID
// 这样用户就不能多次做出相同的反应
body: { reaction }
}),
async onQueryStarted({ postId, reaction }, { dispatch, queryFulfilled }) {
// `updateQueryData` 需要请求接口名称和缓存键参数,
// 所以它知道要更新哪一块缓存状态
const patchResult = dispatch(
apiSlice.util.updateQueryData('getPosts', undefined, draft => {
// `draft` 是 Immer-wrapped 的,可以像 createSlice 中一样 “mutated”
const post = draft.find(post => post.id === postId)
if (post) {
post.reactions[reaction]++
}
})
)
try {
await queryFulfilled
} catch {
patchResult.undo()
}
}
})
})
})
onQueryStarted 处理程序接收两个参数。第一个是请求开始时传递的缓存键 arg。 第二个是一个对象,它包含一些与 createAsyncThunk 中的 thunkApi 相同的字段({dispatch, getState, extra, requestId}),但也包含一个名为 queryFulfilled 的 Promise。这个 Promise 将在请求返回时解析,并根据请求执行或拒绝。
API slice 对象包含一个 updateQueryData 实用函数,可让我们更新缓存值。它需要三个参数:要更新的请求接口的名称、用于标识特定缓存数据的相同缓存键值以及更新缓存数据的回调。 updateQueryData 使用 Immer,因此你可以像在 createSlice 中一样“改变”起草的缓存数据。
我们可以通过在 getPosts 缓存中找到特定的 Post 条目来实现 optimistic update,并“改变”它以增加反应计数器。
updateQueryData 生成一个动作对象,其中包含我们所做更改的补丁差异。当我们 dispatch 该 action 时,返回值是一个 patchResult 对象。如果我们调用 patchResult.undo(),它会自动 dispatch 一个操作来反转补丁差异更改。
默认情况下,我们期望请求会成功。如果请求失败,我们可以 await queryFulfilled,捕获失败,并撤消补丁更改以恢复 optimistic update。
对于这种情况,我们还删除了刚刚添加的 invalidatesTags 行,因为我们 不 希望在单击反应按钮时重新获取帖子。
现在,如果我们快速单击一个反应按钮几次,我们应该会在 UI 中看到每次的数字增量。如果我们查看 Network 选项卡,我们还会看到每个单独的请求也会发送到服务器。
流式缓存更新
我们的最后一个功能是通知选项卡。当我们最初在 第 6 部分 中构建此功能时,我们说过“在真正的应用程序中,每次发生某些事情时,服务器都会向我们的客户端推送更新 ”。 我们最初通过添加 “刷新通知” 按钮来伪造该功能,并让它发出 HTTP GET 请求以获取更多通知条目。
应用程序通常会发出初始请求以从服务器获取数据,然后打开 Websocket 连接以随着时间的推移接收额外的更新。RTK Query 提供了一个 onCacheEntryAdded 请求接口生命周期处理程序,让我们可以对缓存数据实施“流式更新”。我们将使用该功能来实现一种更现实的方法来管理通知。
我们的 src/api/server.js 文件已经配置了一个模拟 Websocket 服务器,类似于模拟 HTTP 服务器。我们将编写一个新的 getNotifications 请求接口来获取初始通知列表,然后建立 Websocket 连接以监听未来的更新。并仍然需要手动告诉模拟服务器 什么时间 发送新通知,所以我们将继续通过单击按钮来强制更新来伪装它。
我们将在 notificationsSlice 中注入 getNotifications 请求接口,就像对 getUsers 所做的那样,只是为了表明它是可能的。
import { forceGenerateNotifications } from '../../api/server'
import { apiSlice } from '../api/apiSlice'
export const extendedApi = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query({
query: () => '/notifications',
async onCacheEntryAdded(
arg,
{ updateCachedData, cacheDataLoaded, cacheEntryRemoved }
) {
// 当缓存订阅开始时创建一个 websocket 连接
const ws = new WebSocket('ws://localhost')
try {
// 等待初始查询解决后再继续
await cacheDataLoaded
// 当从套接字连接到服务器接收到数据时,
// 用收到的消息更新我们的查询结果
const listener = event => {
const message = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
updateCachedData(draft => {
// 插入所有从 websocket 接收到的通知
// 进入现有的 RTKQ 缓存数组
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// 如果 `cacheEntryRemoved` 在 `cacheDataLoaded` 之前解析,则无操作,
// 在这种情况下 `cacheDataLoaded` 将抛出
}
// cacheEntryRemoved 将在缓存订阅不再活动时解析
await cacheEntryRemoved
// 一旦 `cacheEntryRemoved` 承诺解决,执行清理步骤
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = extendedApi
const emptyNotifications = []
export const selectNotificationsResult =
extendedApi.endpoints.getNotifications.select()
const selectNotificationsData = createSelector(
selectNotificationsResult,
notificationsResult => notificationsResult.data ?? emptyNotifications
)
export const fetchNotificationsWebsocket = () => (dispatch, getState) => {
const allNotifications = selectNotificationsData(getState())
const [latestNotification] = allNotifications
const latestTimestamp = latestNotification?.date ?? ''
// 对模拟服务器的调用进行硬编码,以通过 websocket 模拟服务器推送场景
forceGenerateNotifications(latestTimestamp)
}
// omit existing slice code
与 onQueryStarted 一样,onCacheEntryAdded 生命周期处理程序接收 arg 缓存键作为其第一个参数,并接收具有 thunkApi 值的选项对象作为第二个参数。options 对象还包含一个 updateCachedData 实用程序函数和两个生命周期 Promise - cacheDataLoaded 和 cacheEntryRemoved。cacheDataLoaded 在此订阅的 初始化 数据添加到存储时解析。当添加此请求接口 + 缓存键的第一个订阅时,会发生这种情况。只要数据的 1+ 个订阅者仍然处于活动状态,缓存条目就会保持活动状态。当订阅者数量变为 0 并且缓存生存期计时器到期时,缓存条目将被删除,并且 cacheEntryRemoved 将解析。 通常,使用模式是:
- 立即
await cacheDataLoaded - 创建像 Websocket 一样的服务器端数据订阅
- 收到更新时,使用
updateCachedData根据更新 “mutate” 缓存值 await cacheEntryRemoved在最后- 之后清理订阅
我们的模拟 Websocket 服务器文件公开了一个 forceGenerateNotifications 方法来模拟将数据推送到客户端。这取决于知道最新的通知时间戳,因此我们添加了一个可以调度的 thunk,它从缓存状态读取最新的时间戳并告诉模拟服务器生成更新的通知。
在 onCacheEntryAdded 内部,我们创建了一个到 localhost 的真实 Websocket 连接。在一个真实的应用程序中,这可能是你需要接收持续更新的任何类型的外部订阅或轮询连接。每当模拟服务器向我们发送更新时,我们会将所有收到的通知推送到缓存中并重新排序。
当缓存条目被删除时,我们清理 Websocket 订阅。在这个应用程序中,通知缓存条目永远不会被删除,因为我们永远不会取消订阅数据,但重要的是要了解清理对真实应用程序的工作方式。
跟踪客户端状态
我们需要进行最后一组更新。我们的 <Navbar> 组件必须启动通知的获取,而 <NotificationsList> 需要显示具有正确已读/未读状态的通知条目。然而,当我们收到条目时,我们之前在客户端的 “notificationsSlice” reducer 中添加了已读/未读字段,现在通知条目被保存在 RTK 查询缓存中。
我们可以重写 notificationsSlice 以便它侦听任何收到的通知,并在客户端跟踪每个通知条目的一些附加状态。
收到新的通知条目有两种情况:当我们通过 HTTP 获取初始列表时,以及当我们收到通过 Websocket 连接推送的更新时。理想情况下,我们希望使用相同的逻辑来响应这两种情况。我们可以使用 RTK 的 "matching utility" 编写一个 case reducer 来响应多种动作类型。
让我们看看添加此逻辑后的 notificationsSlice 是什么样子。
import {
createAction,
createSlice,
createEntityAdapter,
createSelector,
isAnyOf
} from '@reduxjs/toolkit'
import { forceGenerateNotifications } from '../../api/server'
import { apiSlice } from '../api/apiSlice'
const notificationsReceived = createAction(
'notifications/notificationsReceived'
)
export const extendedApi = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query({
query: () => '/notifications',
async onCacheEntryAdded(
arg,
{ updateCachedData, cacheDataLoaded, cacheEntryRemoved, dispatch }
) {
// 缓存订阅开始时创建 websocket 连接
const ws = new WebSocket('ws://localhost')
try {
// 等待初始查询解决后再继续
await cacheDataLoaded
// 当从 socket 连接到服务器接收到数据时,
// 用收到的消息更新我们的查询结果
const listener = event => {
const message = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
updateCachedData(draft => {
// 插入所有从 websocket 接收到的通知
// 进入现有的 RTKQ 缓存数组
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
// dispatch 一个额外的 action,以便我们可以跟踪 “read” state
dispatch(notificationsReceived(message.payload))
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// 如果 `cacheEntryRemoved` 在 `cacheDataLoaded` 之前解析,则无操作,
// 在这种情况下 `cacheDataLoaded` 将抛出
}
// cacheEntryRemoved 将在缓存订阅不再活动时解析
await cacheEntryRemoved
// 一旦 `cacheEntryRemoved` 承诺解决,执行清理步骤
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = extendedApi
// 忽略 selector 和 websocket thunk
const notificationsAdapter = createEntityAdapter()
const matchNotificationsReceived = isAnyOf(
notificationsReceived,
extendedApi.endpoints.getNotifications.matchFulfilled
)
const notificationsSlice = createSlice({
name: 'notifications',
initialState: notificationsAdapter.getInitialState(),
reducers: {
allNotificationsRead(state, action) {
Object.values(state.entities).forEach(notification => {
notification.read = true
})
}
},
extraReducers(builder) {
builder.addMatcher(matchNotificationsReceived, (state, action) => {
// 添加客户端元数据以跟踪新通知
const notificationsMetadata = action.payload.map(notification => ({
id: notification.id,
read: false,
isNew: true
}))
Object.values(state.entities).forEach(notification => {
// 我们读过的任何通知都不再是新的
notification.isNew = !notification.read
})
notificationsAdapter.upsertMany(state, notificationsMetadata)
})
}
})
export const { allNotificationsRead } = notificationsSlice.actions
export default notificationsSlice.reducer
export const {
selectAll: selectNotificationsMetadata,
selectEntities: selectMetadataEntities
} = notificationsAdapter.getSelectors(state => state.notifications)
有很多事情要做,但让我们一次分解一个变化。
notificationsSlice reducer 目前还没有一个好的方法可以知道我们何时通过 Websocket 收到了新通知的更新列表。因此,我们将导入createAction,专门为“收到一些通知”的情况定义一个新的 action 类型,并在更新缓存状态后 dispatch 该 action。
我们希望为“已完成的 getNotifications”操作和“从 Websocket 接收”操作运行相同的“添加读取/新元数据”逻辑。我们可以通过调用 isAnyOf() 并传入每个 action 创建者来创建一个新的 “matcher” 函数。如果当前操作匹配其中任何一种类型,则 matchNotificationsReceived matcher 函数将返回 true。
以前,我们所有的通知都有一个归一化查找表,UI 将它们选择为单个排序数组。我们将重新利用此 slice 来存储描述已读/未读状态的“元数据”对象。
我们可以使用 extraReducers 中的 builder.addMatcher() API 添加一个 case reducer,只要我们匹配这两种 action 类型之一,它就会运行。在其中,我们添加了一个新的 “read/isNew” 元数据条目,它按 ID 对应于每个通知,并将其存储在 notificationsSlice 中。
最后,我们需要更改从该 slice 中导出的 selectors。我们不会将 selectAll 导出为 selectAllNotifications,而是将其导出为 selectNotificationsMetadata。它仍然从归一化状态返回一个值数组,但是更改了名称,因为项目本身已经更改。我们还将导出selectEntities selectors,它作为 selectMetadataEntities 返回查找表对象本身。当我们尝试在 UI 中使用这些数据时,这将很有用。
通过这些更改,我们可以更新我们的 UI 组件以获取和显示通知。
import React from 'react'
import { useDispatch, useSelector } from 'react-redux'
import { Link } from 'react-router-dom'
import {
fetchNotificationsWebsocket,
selectNotificationsMetadata,
useGetNotificationsQuery
} from '../features/notifications/notificationsSlice'
export const Navbar = () => {
const dispatch = useDispatch()
// 触发通知的初始获取并保持 websocket 打开以接收更新
useGetNotificationsQuery()
const notificationsMetadata = useSelector(selectNotificationsMetadata)
const numUnreadNotifications = notificationsMetadata.filter(
n => !n.read
).length
const fetchNewNotifications = () => {
dispatch(fetchNotificationsWebsocket())
}
let unreadNotificationsBadge
if (numUnreadNotifications > 0) {
unreadNotificationsBadge = (
<span className="badge">{numUnreadNotifications}</span>
)
}
// omit rendering logic
}
在 <NavBar> 中,我们使用 useGetNotificationsQuery() 触发初始通知获取,并切换到从 state.notificationsSlice 读取元数据对象。单击“刷新”按钮现在会触发模拟 Websocket 服务器推出另一组通知。
我们的 <NotificationsList> 也类似地切换到读取缓存的数据和元数据。
import {
useGetNotificationsQuery,
allNotificationsRead,
selectMetadataEntities,
} from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
const notificationsMetadata = useSelector(selectMetadataEntities)
const users = useSelector(selectAllUsers)
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
const date = parseISO(notification.date)
const timeAgo = formatDistanceToNow(date)
const user = users.find((user) => user.id === notification.user) || {
name: 'Unknown User',
}
const metadata = notificationsMetadata[notification.id]
const notificationClassname = classnames('notification', {
new: metadata.isNew,
})
// omit rendering logic
}
我们从缓存中读取通知列表和从通知 slice 中读取新的元数据条目,并继续以与以前相同的方式显示它们。
作为最后一步,我们可以在这里做一些额外的清理 - postsSlice 不再被使用,因此可以完全删除。
至此,我们已经完成了将应用程序转换为使用 RTK Query!所有数据获取都已切换为使用 RTKQ,我们通过添加 optimistic updates 和流式更新来改善用户体验。
你的所学
RTK Query 包含一些强大的选项来控制我们如何管理缓存数据。虽然你可能不需要立即使用所有这些选项,但它们提供了灵活性和关键功能来帮助实现特定的应用程序行为。
让我们最后看一下整个应用程序的运行情况:
总结
- 特定的缓存标签可用于更细粒度的缓存失效
- 缓存标签可以是
'Post'或{type: 'Post', id} - 请求接口可以根据结果和 arg 缓存键提供或使缓存标记无效
- 缓存标签可以是
- RTK Query 的 API 与 UI 无关,可以在 React 之外使用
- 请求接口对象包括用于发起请求、生成结果 selectors 和匹配请求 action 对象的函数
- 响应可以根据需要以不同的方式进行转换
- 请求接口可以定义一个
transformResponse回调来在缓存之前修改数据 - 可以给 Hooks 一个
selectFromResult选项来提取/转换数据 - 组件可以读取整个值并使用
useMemo进行转换
- 请求接口可以定义一个
- RTK Query 具有用于操作缓存数据以获得更好用户体验的高级选项
onQueryStarted生命周期可用于通过在请求返回之前立即更新缓存来进行 optimistic updatesonCacheEntryAdded生命周期可用于通过基于服务器推送连接随时间更新缓存来进行流式更新
下一步
恭喜,你已完成 Redux Essentials 教程!你现在应该对 Redux Toolkit 和 React-Redux 是什么、如何编写和组织 Redux 逻辑、Redux 数据流和 React 使用以及如何 使用 configureStore 和 createSlice 等 API有所了解了。你还应该了解 RTK Query 如何简化获取和使用缓存数据的过程。
第 6 部分中的“下一步”部分 包含指向应用程序创意、教程和文档的其他资源的链接。
有关使用 RTK Query 的更多详细信息,请参阅 RTK Query 使用指南文档 和 [API 参考](https://redux- toolkit.js.org/rtk-query/api/createApi)。
如果你正在寻求有关 Redux 问题的帮助,请加入 Discord 上 Reactiflux 服务器中的 #redux 频道。
感谢你阅读本教程,我们希望你喜欢使用 Redux 构建应用程序!